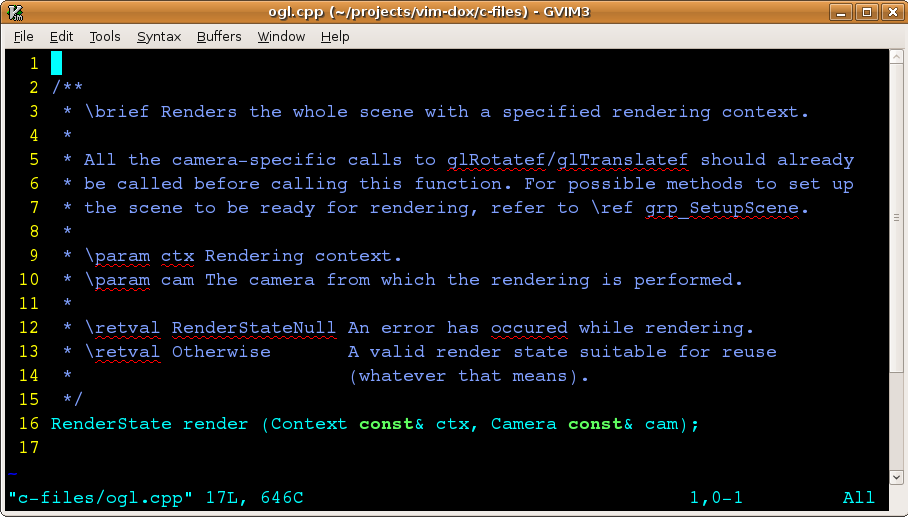
VimDoxSpellMaking Vim and Doxygen and spell checking work!VimDoxSpell is a little program, accompanied with lots of examples and documentation to help you set up your Vim editor to do useful spell checking on a source code tree containing Doxygen comments. This is what you get from Vim out of the box. (OK, this particular
screenshot is from
As you can see, Vim is smart enough not to bother you with spelling errors in the code, only in comments. (Also it checks inside string literals, but that’s irrelevant here). That’s good. And it might be enough when the comments are only for the readers of the particular code snippet. However, Doxygen adds its own noise like “param” and “retval”. Also, it is more important to have accurate spelling in public documentation. Because if you have spelling errors in API docs, you suck. Hence, your code sucks. And even if it doesn’t, it still sucks. The very first step is to figure out that Vim actually does
come with some support for Doxygen out of the box. Only it’s not enabled
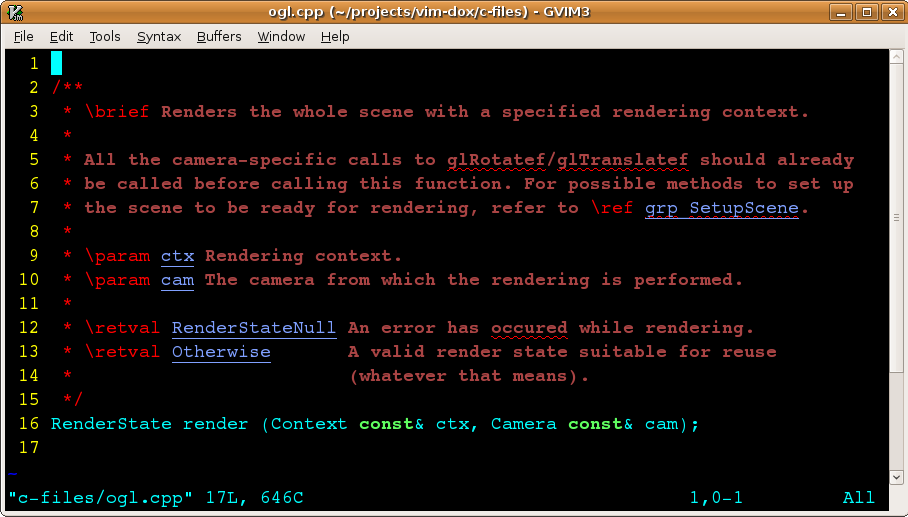
by default. Here’s what you do in your By doing that, you get the following:
Much better, although still not perfect. Things like “param”, “retval” and actual parameter names are no longer specified as false positives. But other things mentioned in your descriptions are. We’ll deal with them below. Another flaw is that you would actually get worse results than
I display here. The problem is that the script to handle Doxygen highlighting,
Now, we need to get rid of other false positives from spell checker. To do that, we’ll need to tag our source code. I use
Exuberant Ctags. Look up your
man page on the usage. It will generate a file named A similar trick is used to get rid of false positives in Doxygen’s
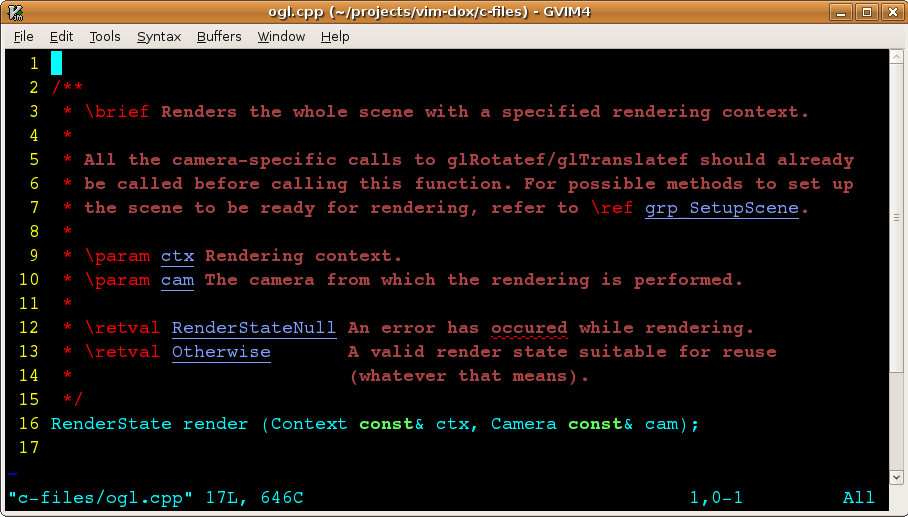
cross references (a Finally, here’s the result after applying VimDoxSpell to your development environment:
Now we see that there is one single typo on this page, as opposed to ten reported in the original screenshot. And not a single false positive! Of course, your mileage may vary with applicability of VimDoxSpell. One thing to consider is the typical identifiers in your code. For example, a popular variable name “wnd” is a very likely typo to the word “end”. And there could be many more of these, that would shadow your actual typos. So you might want to use partial tags file for the purposes of VimDoxSpell. My patch for You might come up with other useful things to add to the dictionary. One good example would be your product names. (The only thing worse than regular typos in documentation are the misspellings of your own product names!). If you come up with an idea to enrich the dictionary that you would like to share with others, let me know. Here is the code. This is the first version being published. It contains the program to convert tags to a dictionary and set other things up. Follow the instructions in the README file to figure out the usage. The package also contains a number of sample files for your consideration. The nature of this software suggests me to put it into public domain. The package you download will almost certainly need to be hacked at least a bit to suit nicely into your development environment. So any other form of licensing would be a burden both for me and for you. So it’s free of any restrictions. However, I would be really grateful if you gave me a credit where due, and let me know if you derive any significant work off of it. |